作者
標題 Re: [新聞] 輝達H100晶片紓壓了 訂單大戶開始轉售
時間 Thu Feb 29 08:06:42 2024
標題 Re: [新聞] 輝達H100晶片紓壓了 訂單大戶開始轉售
時間 Thu Feb 29 08:06:42 2024
千禧年的網路泡沫,也是先炒作硬體商,Cisco, Sun...,Sun還有"dot in dot-com"的廣告。
網路確實是改變世界,但真正大賺的是軟體公司,而且是完全新鮮的軟體公司。
這次AI浪潮,應該也是類似。
N家這次炒作這麼高,是因為真的,Compute是供不應求。每個大公司都怕買不夠,跟不上。
但最近一些AI的發展,也許會發現,這些Compute是不需要的。
Mamba, RetNet, RWKV是從"Attention"的這點來改善。"Attention"是Quadratic Complexity,這是硬體需求的關鍵。現在在找方法從Quadratic改成Linear。
Mamba我很看好,它的作者之一也是"Flash Attention"的作者。
但昨天一篇新的論文,可能是真的翻天覆地的開始。
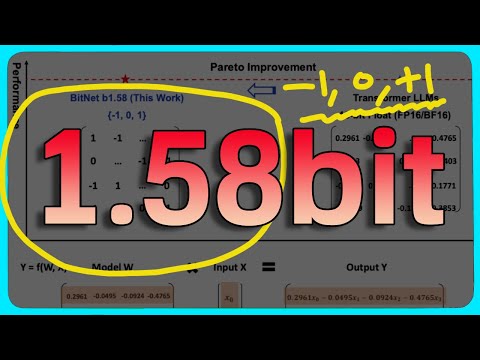
https://arxiv.org/abs/2402.17764
[2402.17764] The Era of 1-bit LLMs: All Large Language Models are in 1.58 Bits Recent research, such as BitNet, is paving the way for a new era of 1-bit Large Language Models (LLMs). In this work, we introduce a 1-bit LLM variant ...
https://news.ycombinator.com/item?id=39535800
hn的討論。
現在討論的共識是,可行,理論基礎很扎實。各路人馬開始指出,從2006年開始的這方面研究,已經找出好多篇證實這方向是可行的。
現在的LLM是用fp16(16bits),這方法可1.58bits,(討論說可以縮到0.68bits)
然後本來是fp dot product的只要int add。
輕鬆10x的效能,新ASIC針對Ternary weight發展可以輕鬆100x的效能改善?
如果這篇證實是可行的,AI起跑點重新設置,所有公司的價值都要重新計算。
如果這篇證實是可行的,AI起跑點重新設置,所有公司的價值都要重新計算。
這篇的作者群很有資歷,但很有趣的是,主要是來自北京/清華大學。美國猛力壓制中國的運力運算,造就不太需要Compute的方法的發現,戳破美國AI泡沫,這會是非常的諷刺。
--
※ 發信站: 批踢踢實業坊(ptt.cc), 來自: 219.70.128.119 (臺灣)
※ 作者: oopFoo 2024-02-29 08:06:42
※ 文章代碼(AID): #1btygMtg (Stock)
※ 文章網址: https://www.ptt.cc/bbs/Stock/M.1709165206.A.DEA.html
※ 同主題文章:
02-28 16:33
Re: [新聞] 輝達H100晶片紓壓了 訂單大戶開始轉售
02-29 08:06
02-29 11:38
02-29 19:01
03-03 01:59
推 : 蒜粒概念股有嗎1F 02/29 08:08
推 : 可惜民進黨逢中必反 根本反智2F 02/29 08:10
推 : 中國沒有a100也可以發論文?3F 02/29 08:11
推 : 嗯,先拿點實際的東西出來看看4F 02/29 08:13
→ : 種蒜用農藥,重返榮耀哪一間我就不說了5F 02/29 08:13
→ : 說得很好 繼續加油啦6F 02/29 08:14
→ fedona …
推 : 這時候崩真的好,大家就可以xdd8F 02/29 08:16
→ : 算力需求根本沒極限 結案9F 02/29 08:16
推 : 可惜民進黨逢中必反 根本反智10F 02/29 08:17
→ : 對於降低資料頻寬的追求跟美國打不打壓沒關係啦11F 02/29 08:17
噓 : 喔12F 02/29 08:18
噓 : 投資那麼多算力,結果沒辦法賺錢,目前很多AI產品的狀況13F 02/29 08:21
推 : 沒有算力才在那邊搞五四三,最終還是回歸算力追求15F 02/29 08:21
噓 : 大紀元16F 02/29 08:21
→ : 跟縮小晶片跟先進封裝兩條線不衝突一樣17F 02/29 08:22
→ : 理論上時光機也做得出來,理論上啦!中或贏,要加油餒…18F 02/29 08:22
推 : 之前以太幣也是出現更有效率的挖礦法 結果沒人再用顯卡挖 AI感覺也是遲早的事20F 02/29 08:23
→ : 美國用這個技術訓練更大的模型?22F 02/29 08:25
噓 : 中文太爛,重寫一遍23F 02/29 08:25
推 : 我很懷疑你到底知不知道自己在講什麼24F 02/29 08:26
→ : 就是沒算力才在那邊搞東搞西的,等這東西真的弄出來,人家瘋狂買算力的都跑多遠了?26F 02/29 08:28
推 : 好了啦 你賺多少28F 02/29 08:29
噓 : 優化架構本來就一直存在 把這個扯成跟打壓晶片有關?問號
還在理論可行沒實作的東西看看就好 不要又搞個超導體笑話29F 02/29 08:30
還在理論可行沒實作的東西看看就好 不要又搞個超導體笑話29F 02/29 08:30
→ : 你是誰33F 02/29 08:30
→ : 這麼說好了 gpu遲早會降價 沒錢的公司可以等價格合理再買阿34F 02/29 08:31
噓 : 又是太監在自慰不用性生活ㄏㄏ36F 02/29 08:31
推 : 大學的論文著重在理論,是的理論!!37F 02/29 08:31
→ : 這文字看了就頭痛38F 02/29 08:32
噓 : 看到吹強國就可以不用看了39F 02/29 08:33
→ : 大大你在電蝦版吹的MSI Claw
好像是跑分80 性能40欸
這樣還賣的比Ally貴是怎樣..40F 02/29 08:33
好像是跑分80 性能40欸
這樣還賣的比Ally貴是怎樣..40F 02/29 08:33
噓 : 說得很好,下次別說了43F 02/29 08:34
推 : 可4現在AI專家們都爽用CUDA欸,而且大力出奇蹟呢44F 02/29 08:34
→ : 跌了就出來透氣了45F 02/29 08:36
噓 : 看到吹強國就知道可以跳過了46F 02/29 08:36
推 : 工程師:改算法太麻煩惹,我們直接大力出奇蹟吧~~47F 02/29 08:37
推 : 戳破再說 先搞個比sora厲害的出來我就相信48F 02/29 08:41
噓 : 補噓49F 02/29 08:44
推 : 好 中國又贏惹 贏兩次50F 02/29 08:45
推 : 之前吹量子 吹爆了改吹AI51F 02/29 08:48
推 : 中國又來贏了,推文有些人又被空氣碰到就高潮跳針民進黨了52F 02/29 08:50
→ : 擋人財路不怕死嗎54F 02/29 08:50
→ : 中或贏55F 02/29 08:50
噓 : 這次跟.com差那麼多56F 02/29 08:50
推 : AI發展到現在只有論文標題愈來愈像農場文是真理57F 02/29 08:52
噓 : 中國還在用算盤解算式嗎?58F 02/29 08:52
噓 : 中共還沒死?59F 02/29 08:54
→ : 寫得不錯 適合丟給AI翻譯一下60F 02/29 08:55
推 : 算力高也不見得做的出好ai,等老黃出算力補偵61F 02/29 08:57
推 : 美國人不習慣省錢62F 02/29 08:57
噓 : 我覺得中國量子電腦搞出後ai就會領先世界 又雙贏63F 02/29 08:57
→ : 現在主要是大家都要搶頭香,agi這種東西第一個做出來的人直接自霸軟體界,一個24小時不休息會思考記憶無限的天才員工,有什麼軟體是他寫不出來的64F 02/29 08:58
→ : 變linear有差,省個運算你以為老黃就會怕了?67F 02/29 08:58
→ : 論文作者一半以上是微軟亞洲研發的員工。我是在釣XD68F 02/29 09:00
噓 : 就中國貪小便宜以為自己聰明!69F 02/29 09:01
推 : 噓的人多少人付費買AI產品過?
我懷疑有1/3就不錯了
chatgpt噓的有多少人是付費會員?70F 02/29 09:02
我懷疑有1/3就不錯了
chatgpt噓的有多少人是付費會員?70F 02/29 09:02
→ : 喔73F 02/29 09:04
推 : 這跟三星超車台g的言論,哪個可信度高?74F 02/29 09:04
→ : 怎麼會覺得算力高的公司沒有在優化自己的程式阿??75F 02/29 09:07
→ : 嘻嘻76F 02/29 09:09
→ : overbooking 丸子77F 02/29 09:16
推 : 量化太多精確度會下降 確定要拿這個講不需要算力嗎78F 02/29 09:16
推 : 我覺得蠻難的,有些問題變interger反而更難79F 02/29 09:22
噓 : 呵呵,信的去放空輝達阿,笑你不敢而已80F 02/29 09:22
推 : 而且運算變簡單不一定等於算力需求降低,反而讓十倍百倍大的模型變的可能,說不定相反變ai爆炸
只是贏家可能換人而已,說不定回頭做fpga了81F 02/29 09:25
只是贏家可能換人而已,說不定回頭做fpga了81F 02/29 09:25
推 : 中國或成最大贏家84F 02/29 09:28
→ thigefe …
推 : 優化是一定要優化 但不代表硬體需求一定會滿足86F 02/29 09:30
噓 : 下次先把吹中國放文章開頭好嗎,省得浪費時間看整篇87F 02/29 09:34
→ : 中又贏88F 02/29 09:35
噓 : 結論:中或贏89F 02/29 09:41
→ : 看起來只有理論 沒有實作? 紙上談兵??90F 02/29 09:41
→ : 中或贏91F 02/29 09:42
→ : 又 這個會否跟ram很像 你說不需要太多ram就能做?
ram是愈多愈好 沒人嫌少92F 02/29 09:42
ram是愈多愈好 沒人嫌少92F 02/29 09:42
→ : 有3.9B的,70B的還在路上。如果這可行,就不需要94F 02/29 09:43
推 : AI又不會向領導敬酒下跪繳紅包,這在共慘就是完全沒用的東西95F 02/29 09:44
→ : GPU做inference。普通CPU就可用了,這是關鍵。97F 02/29 09:44
→ : 彎道超車 拓海還是填海?98F 02/29 09:46
→ : 本來贏者全拿的,現在每個人都有機會。int add很容易的。然後本來是compute限制的,現在回到data限制99F 02/29 09:47
→ : 不是啊...就算真的能無損效能改int, 那改完int省出來的算力我也可以繼續擴增模型尺寸啊, 模型變大能做的事更多更好一樣甩你好幾個車身, 不加大模型我也可以加快運算效率啊, 影片即時翻譯字幕比你快比你精準還是把你壓在地上摩擦, 追根究底算力碾壓的前提下還在妄想什麼彎道超車?202F 02/29 17:40
噓 : 連晶片都要手工的國家,你吹慢慢吹
上次一堆韭菜被詐騙,這次一定不一樣對不對208F 02/29 19:16
上次一堆韭菜被詐騙,這次一定不一樣對不對208F 02/29 19:16
--
作者 oopFoo 的最新發文:
- 108F 26推 21噓
- 69F 11推 7噓
- 49F 17推 4噓
- 254F 55推 55噓
- Intel 限定板 12/12日 aib 12/13日 B580 12GB/20xe2/192bits/pcie5x8 $249鎂 B570 ??? B580想搶3060 12GB的市場。AI的最佳 …105F 44推 1噓
點此顯示更多發文記錄